In my experience as a manager, it is worthwhile to see how people respond to simple, elementary questions in the field they are in. These questions are not an indication of a person’s ability to be a competent software engineer but they are a clear sign of how thorough the engineer is, how they respond to a situation where they don’t know the answer, and most importantly, how deeply the person has mastered their field.
So, there is a good probability that when I am interviewing a developer for machine learning or a data scientist, one my questions will be:
What is the difference between linear regression and logistic regression?
The answer to be complete requires the following:
- Linear regression makes predictions about continuous values (numerical values)
- Logistic regression makes predictions about binary, discrete values (value pairs such as true or false)
- Multinomial logistic regression makes predictions about multiclass, discrete values (discrete values of more than 2 classes)
- Linear regression uses least squares to optimize.
- Logistic regression uses maximum likelihood to optimize.
Extra credit if the following is given:
- Logistic regression uses a Bernoulli distribution.
- Linear regression uses a Gaussian distribution.

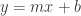 in junior high. I’ve told him that in my opinion, the two deepest insights that he will learn from algebra are this and the quadratic equation.
in junior high. I’ve told him that in my opinion, the two deepest insights that he will learn from algebra are this and the quadratic equation.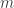 is the slope (whether the line goes up or down) and
is the slope (whether the line goes up or down) and 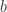 is the
is the 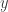 -intercept (the intersection on the
-intercept (the intersection on the 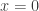 ).
).